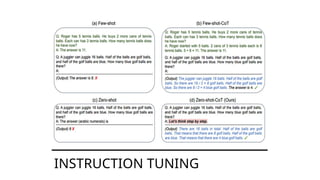
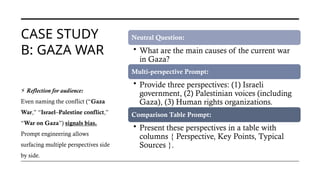
For decades, humans controlled machines with rigid commands: push buttons, type code, configure systems. But with the arrival of Large Language Models (LLMs), a new phenomenon emerged: we can now talk to machines in natural language.
This sounds simple — just ask a question and get an answer.
But here’s the twist: your wording, tone, and structure (your “prompt”) shape the AI’s behavior as much as code shapes a program.
So, are you controlling the AI, or is the AI controlling how you ask?
That’s the central puzzle of prompt engineering — and the journey we’ll explore in this webinar.



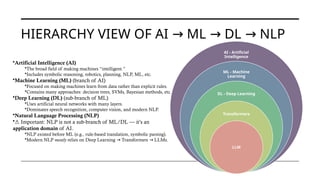



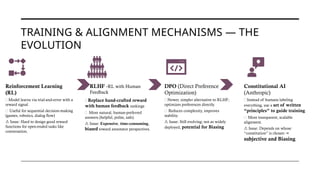
![THE RISE OF
THE
TRANSFORMER
S
• There were two major "winters" approximately 1974–1980 and
1987–2000,[3]
and several smaller episodes, including the
following:1966, 1969, 1971-75, 1973, 1987, 1988, 1990s,
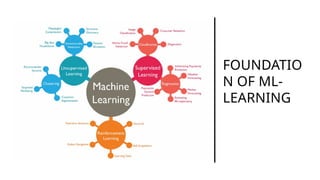
• Beginning about 2012, interest in AI (and especially the sub-
field of machine learning) from the research and corporate
communities led to a dramatic increase in funding and
investment, leading to the current (as of 2025) AI boom.
• Transformers (introduced in 2017, “Attention is All You Need”)
changed everything.(RNN – LTSM – Encoder-Decoder – Enc-
Dec with attention)
They enabled scaling to billions of parameters, making LLMs
like GPT, BERT, and LLaMA possible.
Before
• CNN
• RNN
2017
• Transfo
rmers
2018
• BERT
2018
• GPT
2022
• Chat
GPT](https://image.slidesharecdn.com/doyoucontroltheai-260207152808-5fa92fd6/85/Do-You-Control-the-AI-or-Does-the-AI-Control-You-10-320.jpg)








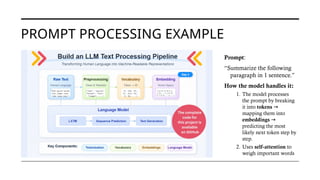
![HOW A PROMPT IS PROCESSED IN AN LLM
•You type the instruction + paragraph.
•Example: “Summarize the following paragraph in 1 sentence.”
1. Prompt Input
•Text is split into small units (tokens).
•E.g. Summarize [Sum, marize], paragraph [para, graph].
→ →
2. Tokenization
•Each token is converted into a numeric vector.
•Position is added so the model knows word order.
3. Embedding + Position Info
•The model looks at all tokens and decides which words matter most.
•Example: “Summarize…1 sentence” gets high attention guides the
→
output.
4. Self-Attention (Transformer
magic ✨)
•The model predicts the most likely next word, step by step.
•Example: it might predict: The, then text, then explains….
5. Prediction (Next Token)
•Depending on settings (greedy, top-k, temperature), it picks words
deterministically or creatively.
6. Sampling / Decoding
• Tokens are converted back into text.
•Final result: a concise, single-sentence summary.
7. Output](https://image.slidesharecdn.com/doyoucontroltheai-260207152808-5fa92fd6/85/Do-You-Control-the-AI-or-Does-the-AI-Control-You-22-320.jpg)